Overall structure of a file in T2C format is shown below.

Typically, a file in T2C format consists of the following parts:
(optional) a header containing T2C directives that define the values of such parameters as
library(name of the library or a system under test of some other kind),libsection(name of the group of functions under test), etc.(optional)
<GLOBAL>section that contains the directives, declarations and definitions common to all the tests;(optional)
<STARTUP>and<CLEANUP>sections that contain initialization and cleanup instructions, respectively, for the group of tests in this file;(mandatory) one or more
<BLOCK>sections that contain the source code of the parameterized test scenarios as well as the values of test parameters.
The source code in <GLOBAL>, <STARTUP> and <CLEANUP> sections is written in the target programming language. It will be inserted verbatim in the appropriate places of the resulting test source file by T2C file generator.
The typical structure of a single <BLOCK> section is as follows.

(mandatory)
<TARGETS>section that contains the list of what is to be tested in this<BLOCK>(usually, a list of functions to be tested there);(optional)
<DEFINE>section that provides symbolic names of test parameters as well as other definitions; in case of C and C++ programming languages, the records in this section are usually translated by T2C into appropriate#definedirectives;(mandatory)
<CODE>section that contains the main part of the parameterized source code of the tests;(optional)
<FINALLY>section that contains per-test cleanup instructions;(optional) zero or more
<VALUES>(or<PURPOSE>) sections that define the sets of values of the test parameters.
Each <BLOCK> defines a parameterized test scenario. If different scenarios are nesessary to check the function(s) under test (the targets of this group of tests), several <BLOCK> sections can be provided for this set of test targets. Generally, it is not recommended to implement significantly different test scenarios in a single <BLOCK>.
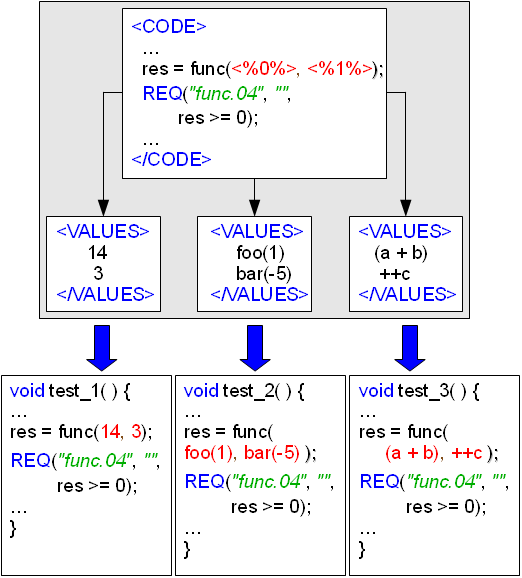
The logic of the group of tests to be created from this <BLOCK> is provided mostly in <CODE> and <FINALLY> sections. These sections are written in the target programming language with one exception: special placeholders can be used in them to refer to the test parameters. For example, T2C file generator will use the value of the parameter #4 in the resulting test source instead of <%4%> placeholder (note that the numbers of parameters start from 0).
However, the placeholders like <%4%> are rarely used directly in <CODE> or <FINALLY> sections. Usually, a symbolic name should be provided for each parameter in the <DEFINE> section (like INDEX and LENGTH instead of <%0%> and <%1%> on the figure above) and then the symbolic names are used in the source of a parameterized test. It often makes the test scenario clearer if the names of the parameters are chosen properly.
For each requirement to be checked in this test scenario, REQ or REQva macro should be called. These macros are provided by T2C API and are used to check requirements and report failures. Among their arguments are the ID of the requirement being checked and the expression that evaluates to 0 if and only if the requirement is violated. If the expression evaluates to 0, the macros output appropriate message about the failure to the test execution log (journal) probably along with the textual representation of the requirement. The latter is loaded from the catalogue of requirements (see Section 3, “Creating catalogue of requirements”).
In case of C or C++ programming language, T2C file generator will usually create a single test function for each set of parameter values defined by <VALUES> and <PURPOSE> sections of the <BLOCK>. The core part of that function will be prepared by substituting the placeholders in <CODE> and <FINALLY> sections with appropriate values. The rest is defined by the templates T2C file generator uses to create the resulting files. The blocks of source code needed to support a particular target testing framework are usually also encapsulated in these templates.
An example of how the actual test functions are created by T2C from the parameterized test scenarios is shown below. Note that in real file generation targets, the resulting test functions are usually defined in a more complex way and contain additional instructions, for instance, to support a particular testing framework, etc.
The values of the parameters of a test scenario should be chosen carefully. Ideally, they should allow to check the system under test in each situation where it is necessary and reasonable.
Among the parameters of a test are often the arguments of the function(s) checked there. Sometimes its expected return value or the expected error code is also a parameter of the test. In more complex cases, even the parts of the test scenario can be made its parameters, for instance, the instructions to properly prepare the data for the function under test, etc. Anything that can be a part of the source code of a test can be made its parameter.
Note
If there are many sets of parameter values provided in a .t2c file, the generated sources of the tests can be quite large in size. It is because of the way T2C operates: for each set of parameter values a test function is generated based on the corresponding parameterized test scenario and placed in the resulting file. It may take a while for a compiler to process such a big file. Some compilers may even refuse to process it.
So, it should be a rule of thumb, to choose the parameters and their values reasonably. Choose them so as to check the system under test in the necessary conditions and at the same time try to keep the number of sets of parameter values not very large. If in fact it starts getting large, you can try to refactor the tests and revisit their parameters to get away with the smaller number of the sets of values.
When writing the source code of a parameterized test, please note that the comments in the target programming language are allowed only in the sections containing the source code in that language: <GLOBAL>, <STARTUP>, <CLEANUP>, <CODE> and <FINALLY>. This is because T2C makes no assumptions about what the target programming language is.
Unlike the comments specific to the target programming language, T2C-style comments can be used anywhere in a .t2c file, even in the header or between sections. T2C-style comments are ignored by the file generator.
A line is a T2C-style comment if in begins with ##. Space and tab characters are allowed before the first '#' character. Example:
## This line is a T2C-style comment.
## This line is a comment too despite the spaces before it.
For compatibility reasons, if a line begins with a single '#' character and does not begin with a directive, it is also considered a T2C-style comment. However, it is strongly recommended to use “##” for the comments to avoid confusion of the readers.
The following directives are currently recognized by T2C (some of them are used by the file generator, the others come from the target programming languages like C, etc.):
- #library
- #libsection
- #additional_req_catalogues
- #if
- #ifdef
- #ifndef
- #elif
- #else
- #endif
- #include
- #define
- #undef
- #line
- #error
- #pragma
- #warning
- #region
- #endregion
A .t2c file may have a special header containing one or more T2C directives. It is not mandatory to specify the header.
The following directives can be used in the header (all of them are optional):
#library<name_of_the_system_under_test>Specifies the name of the system under test (historically, it was often a library). This name may appear in the the generated files, usually in the description of their contents.
Example:
#library libglib-2.0
It is allowed to specify at most one
#librarydirective in a .t2c file.#libsection<name_of_the_section_under_test>Specifies the name of the component (section) of the system under test that is checked in this .t2c file. It can be the name of the group of functions or classes to be tested in this file or something like that. This name may appear in the the generated files, usually in the description of their contents.
Example:
#libsection Arrays
It is allowed to specify at most one
#libsectiondirective in a .t2c file.#additional_req_catalogues<list_of_req_catalogues>Specifies the names of the catalogues of requirements to be used in addition to the default one. The names should be separated by spaces, commas or semicolons.
If the tests use requirement-related T2C API (
REQ,REQva), they may need to specify the location to load the textual representation of the requirements from. The catalogues of requirements are usually expected to reside inreqssubdirectory in the test suite as XML files. The name of each file is the name of the catalogue of requirements it contains, the extension is usually .xml.The default catalogue of requirements for a .t2c file usually has the same name as the .t2c file. The names specified in
#additional_req_cataloguesdirectives are the names of the additional XML files with requirement catalogues to be loaded.Example:
#additional_req_catalogues foo bar; baz
If the directive in the example above appears in file
glib_arrays.t2c, the test executable created from this file will try to load catalogues of requirements from the following files:glib_arrays.xml(default),foo.xml,bar.xml,baz.xml.Note
It should not be considered an error if some or all catalogues of requirements (including the default one) associated with the .t2c file do not exist.
Any number of
#additional_req_cataloguesdirectives are allowed in a .t2c file. If there are two or more of them, the effect is the same as if all the names of catalogues listed in these directives were specified in a single#additional_req_cataloguesdirective.
The directives mentioned above instruct the file generator to create the following parameters with appropriate values: library, libsection and req_cat, respectively. These parameters can be used in the templates from which the resulting files will be created. Note that req_cat can be multivalued, its values being the names specified in #additional_req_catalogues directives.
An example from the main template of test_group template group for c_standalone target. It is a part of the comment to appear at the top of the generated file:
// This file contains tests for the following library: // <$library$>, // section: // "<$libsection$>"
A more complex example from the same template is presented below. Here, an array with the names of catalogues of requirements is defined using req_cat and T2C_FILE_NAME parameters:
const char* rcat_names_[] = {
"<$T2C_FILE_NAME$>",
<$if concat(req_cat)$>"<$req_cat : join(",\n ")$>",
<$endif$>NULL
};
As a result of evaluation of this template fragment, a definition like the following one will be generated:
// time_get.cpp - generated from src/time_get.t2c
const char* rcat_names_[] = {
"time_get",
"LocalizationLibrary",
"LanguageSupport",
NULL
};
<$if concat(req_cat)$>... construct means that the elements after "<$T2C_FILE_NAME$>" will be present in rcat_names_ array if and only if req_cat parameter has at least one non-empty value (or, equivalently, if the concatenation of all values of req_cat is a non-empty string). See Section 5.1.4, “Conditionals” for details.
Note
It is up to the templates and T2C API for a particular T2C target, whether to use these parameters or not and how to interpret them. For example, in c_minimal T2C target, req_cat parameter is ignored because this target does not support output of the text of violated requirements.
See Section 5, “Templates, Template Groups and File Generation with T2C” for the detailed description of template-based file generation mechanism used by T2C.
The contents of <GLOBAL> section will appear in the generated test source file before the tests. If it is necessary to define some global variables, provide type definitions that can be used by the tests, specify C/C++ preprocessor directives, etc., <GLOBAL> section is the proper place for it.
Example:
<GLOBAL>
#include <glib-2.0/glib.h>
guint *some_global_data = NULL;
// GCompareFunc
// A comparison function for array elements (necessary for sorting)
gint array_cmp (gconstpointer a, gconstpointer b)
{
if (a && b)
{
if (*((int*)a) < *((int*)b))
{
return -1;
}
if (*((int*)a) > *((int*)b))
{
return 1;
}
}
return 0;
}
</GLOBAL>
T2C file generator sets the contents of <GLOBAL> section as the value of the parameter named global that can be used by the templates from test_group template group.
The code from <STARTUP> section is called before the group of tests generated from this file begins to execute. Note that it is called only once, before the first test in the group begins.
<STARTUP> section is typically used for the following:
Initialization of global resources used by all or at least several of the tests. In particular, initialization of the objects declared in <GLOBAL> section is often performed here.
Checking if the enviroment in which this group of tests executes is sane. For example, if the tests check some thread-related functionality, <STARTUP> section is a proper place to find out whether threads are supported by the system at all. If not, it perhaps makes no sense to execute this group of tests.
If the initialization of the global resources fails or some other problems are detected in the system under test, it is possible to cancel the execution of the tests from this file. INIT_FAILED( is provided by T2C API for this purpose. It outputs the specified message to the logging facility used by the tests (stderr, in the most simple case) and cancels the execution of the tests.
<message>)
The following example it taken from the tests for OpenType validation support in Freetype 2.x. It checks whether the required module is available in Freetype and if not, cancels the execution of the tests via INIT_FAILED().
<STARTUP>
//Check that the OpenType validation module is available by default.
FT_Library library = NULL;
FT_Error error = 0;
FT_Module mod = NULL;
error = FT_Init_FreeType(&library);
if( (error != 0) || (library == NULL) )
{
INIT_FAILED("Failed to initialize a new FreeType library object.");
}
else
{
mod = (FT_Module)FT_Get_Module(library, "otvalid");
if( mod == NULL )
{
INIT_FAILED("OpenType validation module is not available.");
}
}
if(library)
{
FT_Done_FreeType(library);
}
</STARTUP>
Note
If each test is executed in a separate child process (like it is by default in c_tet, c_standalone and some other T2C targets), the code from <STARTUP> section is executed in the parent process. That is, it may be not suitable for initialization of process-specific (test-specific) resources. It makes more sense to perform such initialization in the test itself rather than in <STARTUP> anyway.
T2C file generator sets the contents of <STARTUP> section as the value of the parameter named startup that can be used by the templates from test_group template group.
<CLEANUP> section allows to specify instructions to do cleaning-up of global resources used by the tests. The code from <CLEANUP> section is called after the group of tests generated from this file finishes. That is, it is called only once, after the last test in the group ends.
Sometimes <CLEANUP> section is also used to perform additional instructions after the tests if some of them may terminate abnormally. If a test terminates this way for some reason, it may not be able to do cleaning-up itself. In this case, the code in <CLEANUP> section should first check if appropriate cleanup is already done by the test, and if not, do it. It may involve deletion of temporary files, lock files, etc.
Note
If each test is executed in a separate child process (like it is by default in c_tet, c_standalone and some other T2C targets), the code from <CLEANUP> section is executed in the parent process. That is, it may be not suitable for cleanup of process-specific (test-specific) resources. It makes more sense to perform such cleanup in the test itself (usually, in <FINALLY>) rather than in <CLEANUP>.
T2C file generator sets the contents of <CLEANUP> section as the value of the parameter named cleanup that can be used by the templates from test_group template group.
Each <BLOCK> defines a parameterized test scenario. Usually it represents a single test case for which one or more individual tests will be created.
Important
It is highly recommended to implement each parameterized test scenario in a separate <BLOCK> rather than mix several scenarios in a single <BLOCK>. In the latter case, the tests are often much harder to understand and maintain.
Sometimes one may be tempted to gather several similar test scenarios in a single <BLOCK> to reuse the parts of the code. However, there are usually better ways to achieve this without sacrificing mantainability. For example, common parts of the test scenarios could be refactored into global functions, classes or whatever else and then used in the tests. In addition, it is sometimes possible to make some of the reusable parts of the code the parameters of the tests, which may help too.
For example, if the tests in a <BLOCK> bristle with conditional constructs like the following, they probably need refactoring:
if (TEST_CASE==1 && TEST_NUM==77) {...}
else if (TEST_CASE==1 && TEST_NUM==78) {...}
else if (TEST_CASE==5) {...}
...
Using the number of the test or the like to select a branch of execution should be avoided anyway.
A similar situation is when a parameter of the test is used only to select a branch to execute:
// 'THE_FUNCTION_MUST_FAIL' parameter is used only to select
// a branch to execute.
if (THE_FUNCTION_MUST_FAIL)
{
// Check the situation where the function must fail.
...
}
else
{
// Check the situation where the function must succeed.
...
}
Splitting the <BLOCK> into several <BLOCK> sections, each for a single test situation, is one of the options to consider in these cases.
Total number of the individual tests generated from a .t2c file is available as num_tests parameter in test_group template group.
Besides that, each test has three numbers (indexes) assosiated with it:
block_indexNumber of the <BLOCK> section the test belongs to in the .t2c file. <BLOCK> sections are numbered in the same order they are listed in the .t2c file.
test_indexNumber of the test in the <BLOCK> section. The tests are numbered in the same order the corresponding sets of parameter values are defined in the <BLOCK> section, namely in the order <VALUES> (or <PURPOSE>) subsections are listed in the <BLOCK>, plus the “depth search” order within the subsections containing SET-constructs.
abs_test_indexThe absolute index of the test in the resulting source file. The order in which this index is assigned corresponds to the order of (block_index, test_index) pairs.
All three indexes begin with 1.
The indexes are available both in test_group (as <$block_index$>, <$test_index$> and <$abs_test_index$>) and test_group (as <%block_index%>, <%test_index%> and <%abs_test_index%>) template groups. Each of these parameter is usually multivalued in test_group template group, it has the same number of values as there are tests generated from the .t2c file. In test_case template group, these parameters have a single value each: they correspond now to a particular test.
These indexes are often convenient to use in the names of the individual tests (test functions, etc.), for example:
////////////////////////////////////////
// This is the test #<%abs_test_index%>
////////////////////////////////////////
static int
test_<%block_index%>_<%test_index%>()
{
...
// The body of the test
...
}
Using the indexes of the tests allows to generate list-like structures for the tests: the arrays of names of test functions, arrays of data structures needed by the tests, etc. Consider the following example from the main template of test_group template group (c_standalone target):
// The list of test functions in this file.
FT2CTestFunc test_func[] = {
<$test_func_item : join(,\n )$>,
NULL
};
test_func_item subtemplate is defined in test_group/test_func_item.tpl as follows:
test_<$block_index$>_<$test_index$>
This allows to create the constructs like the following one in the resulting source file:
// The list of test functions in this file.
FT2CTestFunc test_func[] = {
test_1_1,
test_2_1,
test_2_2,
test_2_3,
test_3_1,
test_3_2,
test_3_3,
test_3_4,
test_4_1,
test_4_2,
test_4_3,
test_5_1,
NULL
};
<TARGETS> section contains the list of what is tested in this test scenario (<BLOCK>): functions, properties, etc.
At least one test target should be defined for each test scenario (<BLOCK>).
The targets are listed one per line. They may contain spaces and tab characters. Leading and trailing spaces and tab characters are ignored. In the following example, <TARGETS> section contains the names of three functions tested in this <BLOCK> section:
<TARGETS>
g_array_set_size
g_array_new
g_array_sized_new
</TARGETS>
Note
These test targets should not be confused with T2C file generation targets (like c_standalone, etc.) These notions are not related.
Many test scenarios have often only one test target. Indeed, if, for example, two target functions can be checked separately, they should better be checked in separate <BLOCK> sections which results in the tests that are usually easier to understand and maintain. However, there can be tightly coupled groups of test targets like getter/setter or open/close functions in which the targets are difficult to test separately. In such cases, several targets can and should be listed for the test scenario.
T2C file generator defines a (possibly multivalued) parameter named target which values are the test targets listed in this section. The parameter can be used by the templates from test_case template group (as <$target$>). In the following example, the list of test targets is placed in the comments before the test function and in TRACE0 call that will output it to the log when the test is executed:
////////////////////////////////////////
// This is the test #<%abs_test_index%>
//
// Target(s):
// <$target : join(,\n// )$>
////////////////////////////////////////
int
test_<%abs_test_index%>()
{
...
// Output the list of test targets
TRACE0("Test target(s):\n <$target : join(\\n )$>\n");
// The rest of the test
...
}
The resulting fragment of the test source file generated using this template may look like this:
////////////////////////////////////////
// This is the test #12
//
// Target(s):
// g_module_open,
// g_module_close
////////////////////////////////////////
int
test_12()
{
...
// Output the list of test targets
TRACE0("Test target(s):\n g_module_open\n g_module_close\n");
// The rest of the test
...
}
Note that it is allowed to use <%…%>-parameters not only in <DEFINE>, <CODE> and <FINALLY> subsections but also in <TARGETS> subsection. For example, assume that the value of parameter <%0%> of the tests may be char or wchar_t. Sometimes it can be convenient to define the test targets the following way to take advantage of parameter substitution:
<TARGETS> basic_string<<%0%>>::basic_string(const allocator<<%0%>>&) </TARGETS>
If the first value (#0) specified in the <VALUES> section is char, the fragment above evaluates to the following:
<TARGETS> basic_string<char>::basic_string(const allocator<char>&) </TARGETS>
On the other hand, if the value of <%0%> is wchar_t, the result will be different:
<TARGETS> basic_string<wchar_t>::basic_string(const allocator<wchar_t>&) </TARGETS>
That is, even the set of targets of a <BLOCK> can be controlled by the parameters of the tests from this <BLOCK>.
Note
This applies to all <%…%>-parameters: numbered test parameters , attributes of the <BLOCK> section, test indexes, etc.
<DEFINE> section is commonly used to provide symbolic names (aliases) for test parameters which are often easier to understand in the test scenario than the references to <%…%>-parameters themselves.
However, <DEFINE> section can serve other purposes as well. In general, its entries just allow to define (name, value) pairs that can be interpreted in a way specific to the chosen T2C file generation target (it is described below in more detail).
Each entry in the section should occupy a single line. The syntax of an entry is as follows:
#define<name><value>
Space and tab characters are ignored before and after “#define” and also after “<name>” and “<value>”.
<%…%>-parameters can be used both in the names and the values in <DEFINE> section.
As it has been said, <DEFINE> section is commonly used to provide human-readable names for test parameters, especially for numbered test parameters coming from <VALUES> (<PURPOSE>) sections.
Consider the following fragment of a test scenario:
int total = <%0%> * <%1%>;
The meaning of that fragment would be easier to understand if we defined symbolic aliases for these numbered parameters:
<DEFINE> #define QUANTITY <%0%> #define PRICE <%1%> </DEFINE>
Now that fragment of the test scenario could be rewritten as follows:
int total = QUANTITY * PRICE;
The meaning of the statement in the fragment above is probably clearer now. So this fragment would be easier to develop and maintain.
For historical and compatibility reasons, the syntax of an entry in a <DEFINE> section resembles #define C preprocessor directive. The entries, however, can be interpreted in a variety of ways depending on the templates used. They can be used even if the target programming language does not have #define directives.
What the file generator does, is to define two (possibly multivalued) parameters named define_name and define_value, respectively, that can be used by the templates from test_case template group (as <$define_name$> and <$define_value$>). Each entry in <DEFINE> section provides corresponding values of these parameters.
Consider the following example of <DEFINE> section:
<DEFINE> #define AAA <%0%> #define BBB val-<%1%>-<%2%> #define CCC some constant value </DEFINE>
Assume the numbered parameters <%0%>, <%1%> and <%2%> have values (without the quotes) “XX”, “YY” and “ZZ”, respectively, in this particular test.
The main template from test_case template group that deals with defines may look like this:
void
test_<%abs_test_index%>()
{
<$define : join(\n)$>
...
// The body of the test
...
<$undef : join(\n)$>
...
}
First, we can define define and undef subtemplates (referred to by the template above) in define.tpl and undef.tpl files as follows:
define.tpl:
#define <$define_name$> <$define_value$>
undef.tpl:
#undef <$define_name$>
When the source code of this particular test will be generated, the result will be as follows:
void
test_1()
{
#define AAA XX
#define BBB val-YY-ZZ
#define CCC some constant value
...
// The body of the test
...
#undef AAA
#undef BBB
#undef CCC
...
}
In the above example, ordinary C preprocessor directives (#define and #undef) were generated. But let us now define define and undef subtemplates differently:
define.tpl:
CObject* obj_<$define_name$> =
CObjectFactory::create_object("<$define_value$>");
undef.tpl:
CObjectFactory::destroy_object(obj_<$define_name$>);
This time the resulting source code of the test will be completely different:
void
test_1()
{
CObject* obj_AAA =
CObjectFactory::create_object("XX");
CObject* obj_BBB =
CObjectFactory::create_object("val-YY-ZZ");
CObject* obj_CCC =
CObjectFactory::create_object("some constant value");
...
// The body of the test
...
CObjectFactory::destroy_object(obj_AAA);
CObjectFactory::destroy_object(obj_BBB);
CObjectFactory::destroy_object(obj_CCC);
...
}
These examples once again demonstrate that the interpretation of the data provided in a .t2c file depends on the templates. Processing the same .t2c file with different sets of templates allows to produce source files that differ very much from each other.
As it is also shown in the above examples, it is not required to use <%…%>-parameters in the entries of <DEFINE> section, neither it is mandatory to use just one such parameter in each entry.
<CODE> section contains the main part of the parameterized test scenario, perhaps except for cleanup (resource deallocation) instructions that are usually placed in <FINALLY> section. The contents of <CODE> and <FINALLY> sections are written in target programming language but they can refer to <%…%>-parameters and often use to what <DEFINE> section evaluates: symbolic names of test parameters or the like.
T2C targets may provide special API that can be used in <CODE> and <FINALLY> sections, for example, to link each check with the requirements that are checked there, to conveniently handle error reporting and other message output, etc. C API provided by several T2C targets is described in Section 4, “T2C File Generation Targets”. It is not required of a target to provide exactly the same or similar API or any API at all.
The code in <FINALLY> should be called both if the test passes and if it fails (probably with the exception of abnormal termination of test application). For example, in c_standalone, c_minimal and some other targets, the instructions in <FINALLY> are called not only when the test passes but also if a violation of a requirement is detected or when the test situation cannot be prepared (“precondition failure”), etc.
It is up to T2C target, how to implement support for <FINALLY>. It may use exception handling, unconditional jumps (goto) or whatever else is suitable. The templates and may be API provided by this target are responsible for this.
T2C file generator sets the contents of <CODE> and <FINALLY> sections as the values of the parameters named code and finally, respectively, that can be used by the templates from test_case template group (as <$code$> and <$finally$>).
<VALUES> sections are used to define the values of test parameters. For compatibility with T2C 1.x, <PURPOSE> sections can also be used with the same meaning and syntax as <VALUES> sections. What is stated below concerning <VALUES> sections, also holds for <PURPOSE> sections.
The value for each parameter should be on a separate line. Blank lines are ignored. Leading and trailing space and tab characters in the entries are ignored too.
More than one value can be specified for a parameter at once, in a single <VALUES> section. See Section 2.7.7, “Specifying sets of values for test parameters (SET and RES constructs)” for details.
Examples:
<VALUES>
## ZERO
FALSE
## CLEAR
TRUE
## TYPE
struct CMyStruct
</VALUES>
<VALUES>
## ZERO
SET(TRUE; FALSE)
## CLEAR
SET(TRUE; FALSE)
## TYPE
SET(int; char)
</VALUES>
Note
It is a good programming practice to place at least the name of the parameter in the comments near its value. It improves readability of the .t2c file.
The entries in <VALUES> section correspond to the numbered parameters of the test. The file generator defines parameter <%0%> for the first entry, <%1%> - for the second one, <%2%> - for the third one, etc. The number of such parameters is limited only by the amount of memory available to the file generator. In practice, the number of such parameters should be kept reasonably small. For example, if a test scenario has 20 or more parameters, it can be difficult to see what is going on in there.
If a test refers to a numbered <%…%>-parameter which is not defined in the corresponding <VALUES> sections (that is, 0-based number of the parameter is greater than or equal to the number of entries in each of these sections), the parameter is considered to have an empty value.
The number of entries in different <VALUES> sections of the same <BLOCK> section should be the same. T2C file generator will report an error if this is not the case. Even if some individual tests do not use a particular parameter which the other tests from this <BLOCK> use, they should still provide some value for it. The value will not affect the test and can be something like “Not used” string to point out that this parameter is not used in this test.
<VALUES> section can be left empty. It indicates that no numbered parameter is defined for the tests from this <BLOCK>.
If no <VALUES> and <PURPOSE> sections are present in a <BLOCK>, it is the same as if one empty <VALUES> section was in this <BLOCK>.
Note
For each set of values of test parameters, an individual test will be created by the file generator. The sources of the individual tests generated from all the <BLOCK> sections in a .t2c file will be placed into a single source file.
Long entries in <VALUES> section can be written in more than one line: they can be broken into smaller parts with a backslash character ( \ ). A backslash affects the next meaningful line in the section (that is, a line that is not blank and is not a T2C-style comment). Note that leading whitespace characters (spaces and tabs) in that line are ignored but the spaces and tabs before the backslash at the previous line are not.
## The following sections are equivalent:
<VALUES>
"prefix" "body" \
"suffix"
1\
2\
3
</VALUES>
<VALUES>
"prefix" "body" "suffix"
123
</VALUES>
<VALUES>
"prefix" "body" \
"suffix"
1\
## one
2\
## two
3
</VALUES>
A backslash after the last entry in the section is ignored, so the following example sections are equivalent:
<VALUES>
TRUE
TRUE
int \
</VALUES>
<VALUES>
TRUE
TRUE
int
</VALUES>
If one or more backslashes are the last characters of the value rather than line-breaking markers, the last one of them should be escaped (again with a backslash). Example:
## Here the following values are defined:
## "string\\"
## "TRUE"
## rather than "string\\TRUE"
<VALUES>
string\\\
TRUE
</VALUES>
Important
<%…%>-constructs are not interpreted as parameter references in the entries in <VALUES> sections. Such constructs are taken literally there.
For each set of values of test parameters, the file generator defines additional <%…%>-parameter named param. It has the same number of values as there are entries in the corresponding <VALUES> section, the values being the values of the respective numbered parameters of the test. The order is the same as the order of entries in the <VALUES> section: the first value of param is that of <%0%> parameter, the second one is the value of <%1%>, etc.
This parameter can be used by the templates from test_case template group to create the list of parameter values for each particular test (usually in the description of the test in the comments) or other similar list-like structures. Consider, for example, the following fragment of the main template from test_case group (the template of a comment block before the test):
/////////////////////////////////////////////////////////////////// // This is the test #<%abs_test_index%> // // Target(s): // <$target : join(,\n// )$> // // Parameters: // <%if concat(param)%><%param : join(,\n// )%><%else%>none<%endif%> ///////////////////////////////////////////////////////////////////
The resulting fragment of the source file may look like this:
///////////////////////////////////////////////////////////////////
// This is the test #2
//
// Target(s):
// g_module_open,
// g_module_close
//
// Parameters:
// GET_PATH("open-symbol-close/module/test.so"),
// G_MODULE_BIND_LAZY,
// "test"
///////////////////////////////////////////////////////////////////
In the above fragment, the values of parameters <%0%>, <%1%> and <%2%> are listed after the line “// Parameters:”, on a separate line each, separated by commas.
If there are no entries in the corresponding <VALUES> section, the resulting fragment of the source file may look like this:
/////////////////////////////////////////////////////////////////// // This is the test #30 // // Target(s): // g_module_supported // // Parameters: // none ///////////////////////////////////////////////////////////////////
A <BLOCK> section can have user-defined attributes that can be used in the tests generated from that section.
Example:
<BLOCK name = "My Super Test"
depth = "medium"
min_ver="2.0.1"
max_ver="3.9.99"
>
In this example, four attributes are defined (the format is <name>="<value>", the quotation marks are not included in the value).
A name of an attribute may containg latin letters, digits, dots, underscores, hyphens, etc. It must not begin with a dot or a parenthesis. The names are case-sensitive. In fact, it must be valid as a name of T2C template or parameter (see Section 5, “Templates, Template Groups and File Generation with T2C”), the rules are the same here.
Note
It is not allowed to define more than one attribute with a particular name in a <BLOCK>.
The value of an attribute must not contain quotation marks. No escaping of such characters is currently supported there.
The attributes can be used in the same way as the numbered parameters of the tests (<%0%>, <%1%>): <%name%>, <%depth%>, etc.
Example:
<CODE>
...
printf("<%name%>: some message\n");
printf("<%name%>: par0 = %s\n", "<%0%>");
...
</CODE>
As with any other parameters in the T2C templates, if an attribute is not specified but is used in a <BLOCK>, its value is assumed to be an empty string.
The attributes can be used both in the parameterized test scenarios and in the templates (“test case” group) from which individual tests are generated. Often these attributes are more useful in the templates rather than in test scenarios themselves.
For example, assume that the tests from each <BLOCK> may have restrictions on the version of the system under test they are applicable for. The minimum and/or maximum acceptable version could be specified in the attributes of these <BLOCK> sections, say, “min_ver” and “max_ver”, respectively. If one or both of these attributes are not specified or have an empty value, this means there are no restrictions on the respective version.
A template of an individual test (main template from “test case” group) could contain the following to automatically check if the test is applicable to a current version of the system (imagine that check_version() function is provided to check that):
void
test_function()
{
...
if (check_version("<%min_ver%>", "<%max_ver%>") != VERSION_SUPPORTED)
{
return; // Do not run the test.
}
...
//the code from <CODE> and <FINALLY> goes here
...
return;
}
So, in this case, the test developer only needs to specify these attributes in the <BLOCK> sections and the code dealing with version checking will appear in the tests automatically.
Multiple values can be specified for a parameter in the <VALUES> subsection of a <BLOCK> in a .t2c file. The file generator will create several sets of parameter values and hence several individual tests based on this <VALUES> section. It looks like as if there were appropriate number of <VALUES> sections, each of which containing a single value for each parameter of the test.
For example, the following fragments are equivalent:
Fragment 1:
<VALUES>
1
SET(TRUE; FALSE; UNKNOWN)
"yes"
</VALUES>
Fragment 2:
<VALUES>
1
TRUE
"yes"
</VALUES>
<VALUES>
1
FALSE
"yes"
</VALUES>
<VALUES>
1
UNKNOWN
"yes"
</VALUES>
That is, SET-constructs are just the means to specify the parameter values in a more compact and systematic way, thus reducing the number of required <VALUES> sections.
SET-constructs can be used for any parameters of the tests. The basic form of a SET-construct is as follows.
SET(<value> [; <value>]*)
The only characters allowed after the ending parenthesis (on the same line) are spaces, tab characters and semicolons.
Note
“SET” and “RES” keywords are case sensitive.
A value in a SET or RES-construct can be enclosed in single ( ' ) or double ( " ) quotation marks. T2C file generator treats the quoted substring as a single value. The quotation marks are treated as a part of the value. That is, they are not stripped when the value is placed in the resulting source file.
A semicolon is considered a separator within the construct except when it is a symbol in a string enclosed in single ( ' ) or double ( " ) quotation marks. For example, the semicolon is not a separator in SET("aaa;bbb").
Let us consider the following example:
SET("ab;c"; "de"; ';'; 'ef')
This SET-construct defines four values:
"ab;c" "de" ';' 'ef'
Spaces and tab characters are allowed at both sides of a separator or opening and closing parentheses.
SET-constructs can also be used for more than one parameter of the test, or even for all of them. The resulting sets of parameter values are obtained by the “cartesian product” in this case. The sets of values are created in a “depth search” order. Consider the following fragment, for example:
<VALUES>
SET(TRUE; FALSE)
SET(0; 1)
"yes"
SET(int; char)
</VALUES>
It specifies eight sets of parameter values in the following order:
(TRUE; 0; "yes"; int) (TRUE; 0; "yes"; char) (TRUE; 1; "yes"; int) (TRUE; 1; "yes"; char) (FALSE; 0; "yes"; int) (FALSE; 0; "yes"; char) (FALSE; 1; "yes"; int) (FALSE; 1; "yes"; char)
The individual tests generated from this <VALUES> section will go in the same order in the resulting source file. This is also essential for RES-constructs described below: it defines the order in which the values in RES-constructs should be specified.
A range of integer values can also be specified for a parameter in a SET-construct. For example, the following construct indicates that values of the parameter are all integer numbers from -15 to 12 inclusive:
SET(-15 .. 12)
Ranges can be combined with ordinary lists of values, for example:
SET(7; -1..5; 10..12; 18)
The boundaries of a range must be specified explicitly as numeric values. Neither expressions nor constant names or whatever else are allowed. For example, T2C file generator will consider that the following constructs define a single value each (E_VALMIN..E_VALMAX and (YYY+ZZZ)..128, taken literally):
SET(E_VALMIN..E_VALMAX) SET((YYY+ZZZ)..128)
Let us consider the following example. Assume myfunc() function is to be tested and this function is declared as follows:
int myfunc(int arg1, int arg2)
It is a common practice to make the arguments of a function under test the parameters of the corresponding test scenarios. Assume these parameters are ARG1 and ARG2 in this case. Let's specify the values of these parameters in the <VALUES> section using SET-constructs, for example:
<VALUES>
## ARG1
SET(0; 3)
## ARG2
SET(10; 20)
</VALUES>
We have defined four sets of values this way:
(0; 10) (0; 20) (3; 10) (3; 20)
It is sometimes convenient to make the expected (i.e. correct) return value of a function under test (myfunc()) a parameter of the test too. The question is, how we can define the set of values of such parameter if we need to specify more than one value. A SET-construct cannot be used for this purpose because in this case, the corresponding <VALUES> section would define not the required four but rather 16 sets of values (due to the “cartesian product” applied to the contents of the three SET constructs) which is not what is needed.
It is recommended to use a RES-construct in this case (“RES” is from “result”), for example:
<VALUES>
## ARG1
SET(0; 3)
## ARG2
SET(10; 20)
## EXPECTED_RESULT
RES(4; 8; 12; 16)
</VALUES>
This way, we define the following sets of values of parameters (ARG1; ARG2; EXPECTED_RESULT):
(0; 10; 4) (0; 20; 8) (3; 10; 12) (3; 20; 16)
The basic form of a RES-construct is quite similar to that of a SET-construct.
RES(<value> [; <value>]*)
The rules for using quotation marks and separators (semicolons) are also the same in SET and RES constructs.
Note
RES-constructs can be used not only for the expected results of the functions being tested but, in general, for any parameters of a test that depend somehow on other parameters of the test.
The values should be listed in RES-constructs in the same order that is used to generate the sets of values from the SET-constructs (“depth search” order, see above). Ranges of values are not allowed in RES-constructs.
If a RES-construct contains less values than needed, the last one is used in the remaining sets of values. If there are more values in a RES-construct than it is necessary, appropriate number of the first values is used, the remaining ones are ignored. For example, the following <VALUES> sections are equivalent:
<VALUES>
SET(0; 3)
SET(10; 20; 30)
## Less values than is defined by SET constructs,
## the last one will be used several times.
RES(4; 8)
</VALUES>
<VALUES>
SET(0; 3)
SET(10; 20; 30)
## Exactly the same number of values
## that is defined by SET constructs
RES(4; 8; 8; 8; 8; 8)
</VALUES>
<VALUES>
SET(0; 3)
SET(10; 20; 30)
## More values than is defined by SET constructs,
## the last 3 values will be ignored.
RES(4; 8; 8; 8; 8; 8; 9; 10; 11)
</VALUES>
You can also specify how many times a particular value listed in a RES-construct should be used. To do this, place a colon after this value and specify the number of times after it (a positive integer). For example, the following construct
RES(10 : 2; 5; 8 : 3; 0)
is equivalent to this one:
RES(10; 10; 5; 8; 8; 8; 0)
Note
If the number of times is specified incorrectly (for example, if there are non-digit characters right after the colon), T2C file generator may interpret this as a single value: “2:a10”, etc.
RES-constructs refer to all SET-constructs in the <VALUES> section, no matter in which order they are listed. In each of the three fragments given below, the RES-construct refers to both SET-constructs:
Fragment 1:
<VALUES>
SET(0; 3)
RES(4; 8)
SET(10; 20)
</VALUES>
Fragment 2:
<VALUES>
RES(4; 8)
SET(0; 3)
SET(10; 20)
</VALUES>
Fragment 3:
<VALUES>
SET(0; 3)
SET(10; 20)
RES(4; 8)
</VALUES>
Double and single quotes and backslashes that occur in the values defined by SET and RES constructs should be escaped with backslash ( \ ) character if otherwise it would be ambiguous how to interpret the construct. Namely,
A backslash character ( \ ) itself can be escaped if it occurs within a string enclosed by single quotation marks ('…') or by double quotation marks ("…") but this is optional. Examples:
## defines "abc\de" SET("abc\\de") ## defines "abc\de" SET("abc\de") ## defines 'abc\de' SET('abc\\de') ## defines 'abc\de' SET('abc\de')A backslash character should be escaped if it occurs just before the ending single or double quotation mark of a string or if there are two or more consequent backslash characters. Examples:
## defines "abcde\" SET("abcde\\") ## defines 'abc\de' SET('abcde\\') ## defines 'abc\\de' SET('abc\\\\de')A double quotation mark ( " ) should be escaped if it occurs within a string enclosed by double quotation marks. Example:
## defines "Hello" "World" (a single value) SET("Hello\" \"World")A single quotation mark ( ' ) should be escaped if it occurs within a string enclosed by single quotation marks. Example:
## defines 'a' 'b' 'c' (a single value) SET('a\' \'b\' \'c')In all other cases, no escaping should be done. Examples:
## defines "'a' 'b' 'c'" SET("'a' 'b' 'c'") ## defines '\"' SET('\"') ## defines \n\r\t SET(\n\r\t)